医学图像处理的会议
https://2022.midl.io/call-for-papers.html
Medical Imaging with Deep Learning
MIDL 长论文 提交deadline 12月 短论文三页 4月22号。
https://2022.midl.io/call-for-papers.html
Medical Imaging with Deep Learning
MIDL 长论文 提交deadline 12月 短论文三页 4月22号。
2021.12.23-12.25
重叠与密集细胞区域的检测文献调研。
调研了两篇密集区域目标检测的文章
PS-RCNN 两个阶段来分别检测未遮挡与严重遮挡的目标
迭代检测的方法,将历史的特征图卷积后作为第二次的输入
查看一下目前faster-rcnn的所有密集、重叠区域检测结果的情况,挑选出了一些检测结果差的样本。
2021.12.25~2021.12.31
密集、重叠细胞区域存在的检测难点,严重遮挡的细胞智能提供较少的视觉信息,检测得到的置信度低,容易被NMS最大值抑制去除。其中一种解决方案是Soft-NMS,Soft-NMS按照检测框之间的重合程度(IOU)进行置信度衰减,但是衰减的形式为人工设计,具有较大的局限性,且置信度降低的检测框后续也可能因不满足置信度阈值的要求而被去除。
针对密集、重叠细胞区域存在的检测失效的问题,拟采用迭代检测的方法来检测两组具有不同遮挡的细胞实例。第一轮检测没有遮挡或者轻微遮挡的细胞,在实例分割分支会得到的已检测到细胞的mask,之后采用该mask去覆盖原特征图的相应位置得到masked feature。在第二轮检测中使用masked feature去检测被遗漏的遮挡较严重的细胞。通过这样的迭代检测方式去提升网络对被遮挡细胞的检测能力。

在该迭代检测的方法中,需要细胞边界的mask信息,因此需要使用语义分割进行细胞的位置标注。
先完成结果写入到labelme的json的形式,完成结果的迭代,目前完成细胞质标注约500余张,版本一迭代完成,形成了闭环,下图为mask-rcnn推断的结果,红色为细胞,绿色为细胞核。

跑一下带有mask的检测网络如mask-rcnn
1 | python tools/train.py configs/mask_rcnn/mask_rcnn_r50_fpn_2x_coco.py --work-dir ./work_dir/mask_rcnn_new/ |
12.29检测结果出现了问题
coco数据集的官网https://cocodataset.org/
1 | "annotations": [ |
标注的信息
cocoapi提供了将polygon转为rle格式的代码 annToRLE
labelme中通过group来判断边界框与mask的归属性。
pycococreator
跑通了mask-rcnn跑出的分割结果是与图片大小相同的mask
coco中imgToAnns记录了某一个img_id对应所有的ann_id
_parse_ann_info包含了一张图片的所有的bbox与segm信息
result2json将检测与分割的结果写为coco的json格式。
model.show_result展示检测结果
对于处于边界的细胞,完整程度要大于5/6
对于细胞质非常小,几乎不可见的细胞种类,不标注细胞核,直接标注为细胞cell
如何制作数据集https://github.com/spytensor/prepare_detection_dataset
将labelme格式的数据转化为coco格式数据,需要对文件进行改写。
// 修改类别,修改image字段 修改area
1 | annotation['area'] = annotation['bbox'][2] * annotation['bbox'][3] |
json编辑器dadroit
通过目录的软连接将数据创建到data文件夹下
https://blog.csdn.net/duanyajun987/article/details/97659685
修改mmdetection/mmdet/datasets/coco.py CLASSES
mmdetection/mmdet/core/evaluation/class_names.py 修改
1 | def coco_classes(): |
修改configs/models/retinanet_r50_fpn.py
1 | num_classes=11, |
训练数据集
1 | python tools/train.py configs/retinanet/retinanet_r50_fpn_1x_coco.py --work-dir work_dirs --resume-from work_dirs/latest.pth --gpus 2 |
多卡训练
1 | bash ./tools/dist_train.sh configs/retinanet/retinanet_r50_fpn_1x_coco.py 2 --work-dir work_dirs --resume-from work_dirs/latest.pth |
查看显卡使用情况
1 | watch -n 1 -d nvidia-smi |
真正的训练文件mmdet/apis/train.py
修改epoch configs/_base_/schedules/schedules_1x.py的runner = dict(type='EpochBasedRunner', max_epochs=240)修改epoch数量
修改batchsizeconfigs/datasets/coco_detection.py samples_per_gpu参数
1 | data = dict( |
1 | python tools/test.py configs/retinanet/retinanet_r50_fpn_1x_coco.py checkpoints/retinanet_r50_fpn_1x_coco_20200130-c2398f9e.pth --show |
1 | python tools/test.py configs/retinanet/retinanet_r50_fpn_1x_coco.py work_dirs/latest.pth --out test_result/latest.pkl --eval bbox --show-dir detect_results |
mmdetection 结果炫酷可视化
热力图(好看的colorbarhttps://www.cnblogs.com/zb-ml/p/13561449.html)
1 | docker run -dit --name sty_cell --gpus all -p 10022:22 --shm-size=16g -v /mnt/sda/sty/data:/Data nvidia/cuda:11.2.2-cudnn8-devel-ubuntu18.04 |
创建docker环境,安装anaconda,安装mmcv mmdet
修改 /mmdet/datasets/coco.py
1 | CLASSES = ( 'Prim', 'Lym', 'Mono', 'Plas', 'Red','Promy','Myelo','Late','Rods','Lobu','Eosl') |
修改config/_base_/models/faster_rcnn_r50_fpn.py
1 | num_classes=11 |
指定GPU训练数据集
1 | CUDA_VISIBLE_DEVICES=1 python tools/train.py configs/faster_rcnn/faster_rcnn_r50_fpn_2x_coco.py --work-dir work_dir/faster_rcnn |
{‘bboxes’: array([[119., 111., 244., 252.]], dtype=float32), ‘labels’: array([8]), ‘bboxes_ignore’: array([], shape=(0, 4), dtype=float32), ‘masks’: [[[119.0, 111.0, 244.0, 252.0]]], ‘seg_map’: ‘ER0437_233.png’}
1 | python tools/test.py configs/faster_rcnn/faster_rcnn_r50_fpn_2x_coco.py work_dir/faster_rcnn/epoch_80.pth --work-dir . --out ./tmp.pkl |
1 | python tools/analysis_tools/analyze_results.py configs/faster_rcnn/faster_rcnn_r50_fpn_2x_coco.py ./tmp.pkl ./results |
1 | python tools/train.py configs/faster_rcnn/faster_rcnn_r50_fpn_2x_coco.py --work-dir/ ./work_dirs/faster_rcnn1 |
COCO数据集标注文件有三种信息
annotations标注的列表
1 | { |
categories标注列表
1 | { |
images列表
1 | { |
coco_eval做了些什么?
首先创建哈希表,_gts与_dts键位image_id与category_id,值为标注与预测bbox与类别信息。
对结果进行分析
单纯用Precision与Recall评价检测器并不公平,AP计算了不同Recall下的Precision,综合性地评价了检测器,PR曲线,对所有BBox给出的置信度从高到低进行排序,当把置信度取某一个值S时,依次对前n个大于置信度的BBox计算Precison与Recall得到一组(P, R)结果。在计算AP时,都要对P-R曲线做一次修正,将P值修正为当r>R时最大的P
$$
Precision = \frac{TP}{TP + FP} \
Recall = \frac{TP}{TP + FN} \
AP = \int_{0}^{1} \max({P(r) | r \ge R}) dR
$$
对于BBox是TP还是FP的算法判断,如某一个BBox预测的label为1,则需要计算其与该图片中所有label为1的GT Box的IOU值,当大于iou_thres时,则该预测box为TP,否则为FP。当某一个GT被置信度最大的BBox匹配后,会从GT Box集合中移除。
TP + FN为测试集中该种类的样本的个数,因此不需要计算FN的个数,一个BBox与GT BOX是一一对应的,最后未检出的GT为FN
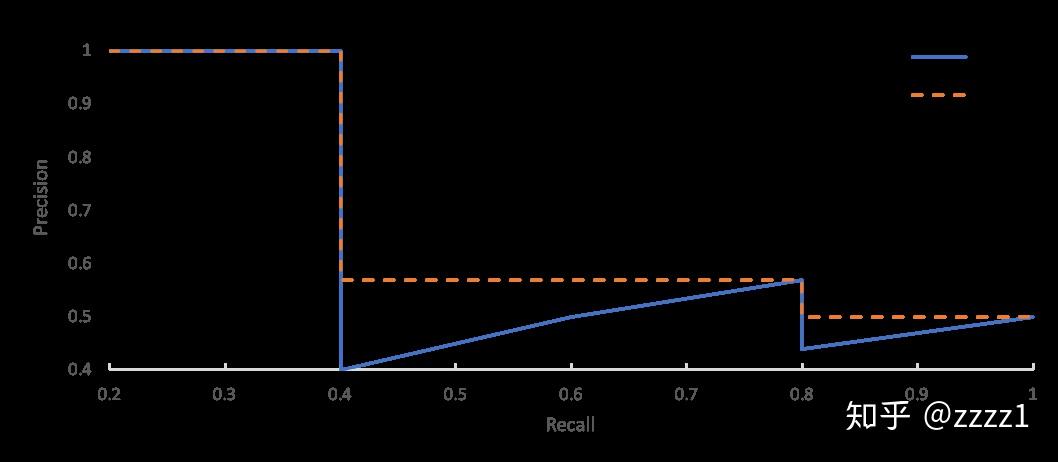
类别平衡问题,mAP,所有类别的检测性能(AP)取平均,就是检测算法在这个IOU下的性能。
不同场景下对预测位置准确度的要求不同。 mmAP,设置一组iou阈值,每一个IOU
https://zhuanlan.zhihu.com/p/60707912 画出不同IOU下的PR曲线。
可以计算一个mAP,对这些性能取平均,在coco数据集中,mAP的计算针对10个IOU阈值下的AP取平均值np.linspace(0.5, 0.95, 10)。
https://zhuanlan.zhihu.com/p/64551412
$\qquad$Tensor多维数组底层实现是使用一块连续内存的1维数组,Tensor在元信息里保存了多维数组的形状,在访问元素时,通过多维度索引转化成1维数组相对于数组起始位置的偏移量即可找到对应的数据。
$\qquad$某些Tensor操作(如transpose、permute、narrow、expand)与原Tensor是共享内存中的数据,不会改变底层数组的存储,但原来在语义上相邻、内存里也相邻的元素在执行这样的操作后,在语义上相邻,但在内存不相邻,即不连续了(is not contiguous)。
1 | def window_partition(x, window_size): |
以上述代码为例,在permute后,只是改变了tensor的元信息,现坐标相对于一维数组的变化,上述代码permute后,每个坐标对应的stride会发生改变。stride可以理解为每个下标的权重。
数组 t 在内存中实际以一维数组形式存储,通过 flatten 方法查看 t 的一维展开形式,实际存储形式与一维展开一致。
骨髓血细胞检测难点
convolutional filters are expected to be informative combinations by fusing spatial and channel-wise information together within local receptive fields.
自适应的调整通道间的相应,通过对通道间的相关性进行建模。