计算机视觉(computer Vision)
1.全连接与CNN模型比较
好久没弄过深度学习的东西了,上次写得时候应该是大三上学期,一转眼就是两年了。感觉自己的记忆力好差啊,之前搞得那些已经是忘得一干二净了。这次的任务是采用Omniglot数据集进行手写数字的识别,该数据及包含了50中字母系统中共计1623种字符,每个字符有20个样本,部分样本如下图所示。

我采用的深度学习框架是pytorch,当用户使用DataLoader加载自定义数据时,需要继承Dataset这个类,并重写其中的两个方法。传入参数为图片路径与标签的字典。采用DataLoader()加载数据,batch_size大小设置为64。
1 | def __getitem__(self, index): |
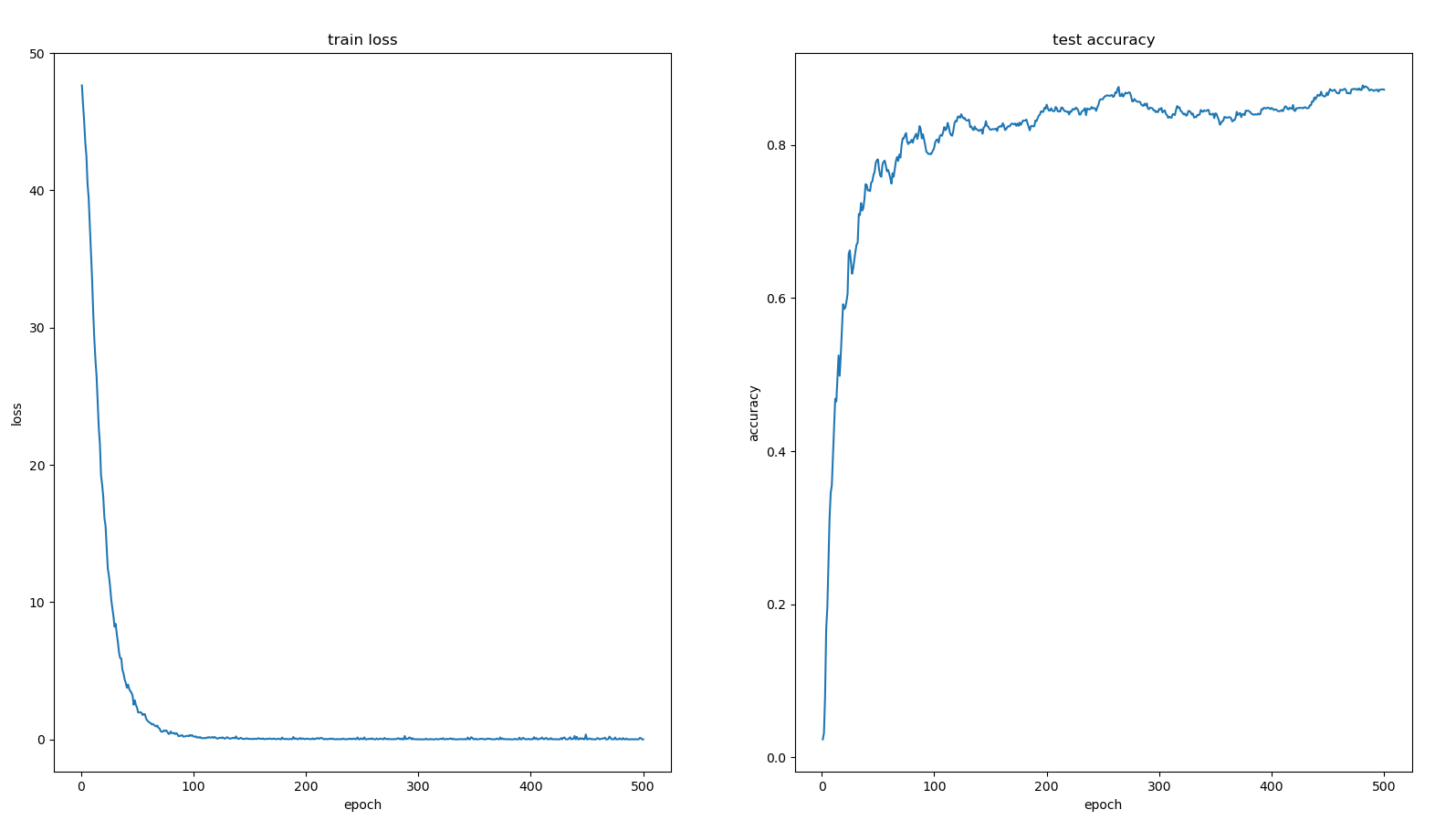
定义包含一个隐层的全连接模型, 训练50个epoch,训练集上的loss与测试集上的accuracy如下图所示,全连接模型测试集的准群率在40%左右。
1 | model = nn.Sequential( |
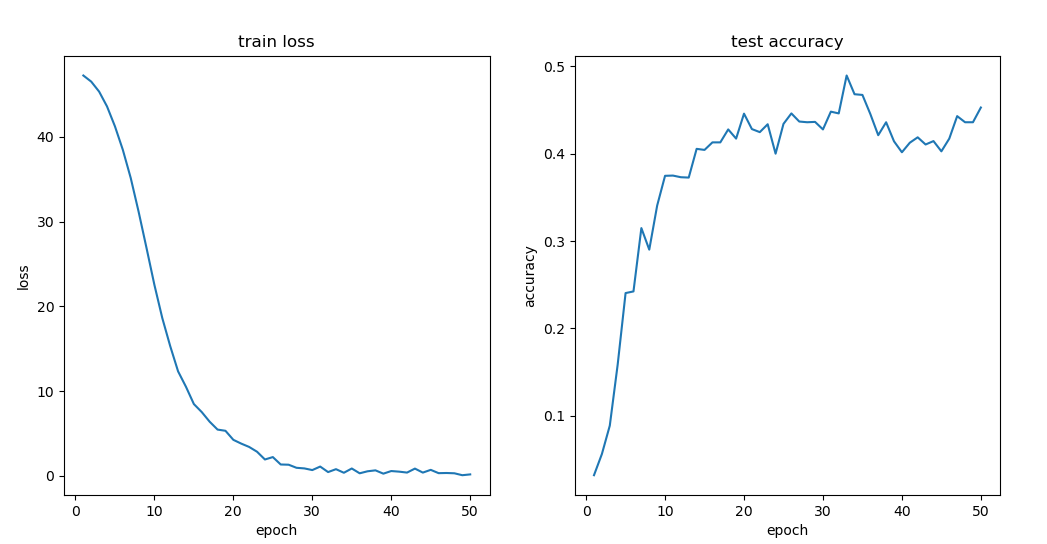
定义包含四个卷积层与两个全连接层的CNN网络, 训练50次,测试集上的最高准确率为0.8389,相比于全连接模型,准确率大大提升。
1 | def forward(self, x): |
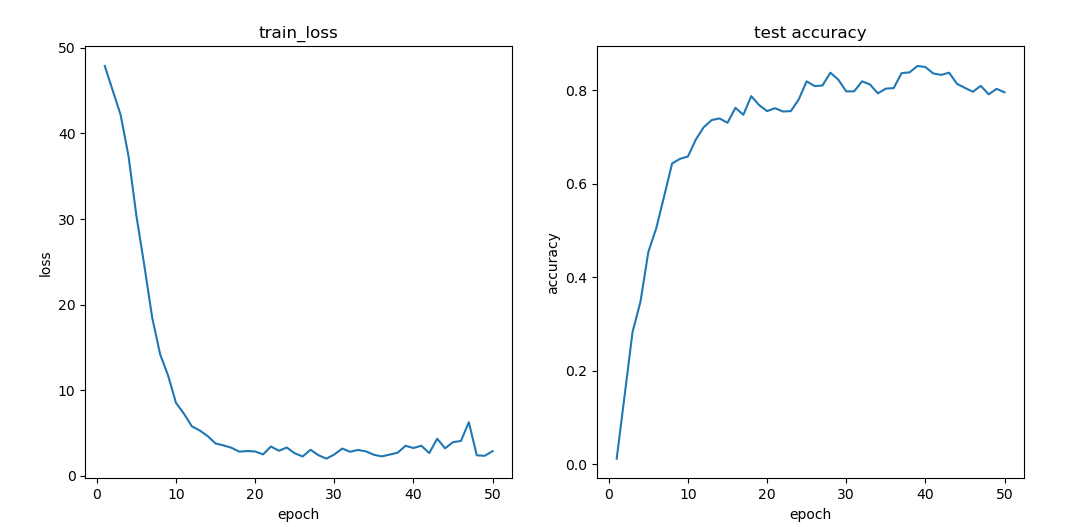
2.尝试与对比
2.1数据集的划分
将类别设置为20类,每个类别训练集为15个样本,测试集为3个样本,结果如下图所示,分类准确率相比于50类明显提升,最高为0.9314。适当的减少分类类别可以提升模型的分类准确率。
2.2改变模型结构
相比于示例给出的卷积网络,再加入一卷积层,结果如下,分类准确率变化不大。
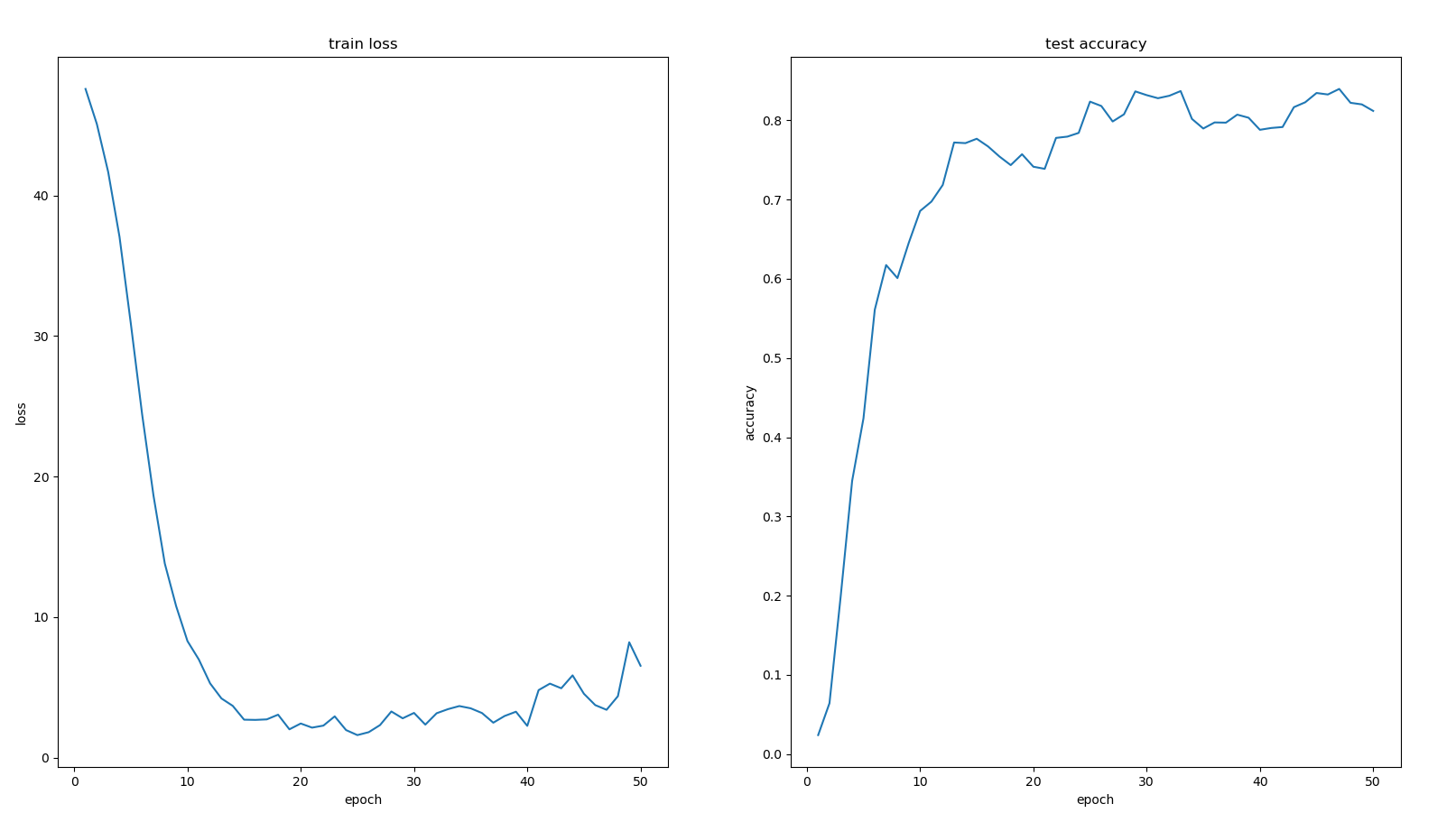
2.3 不同的优化器比较
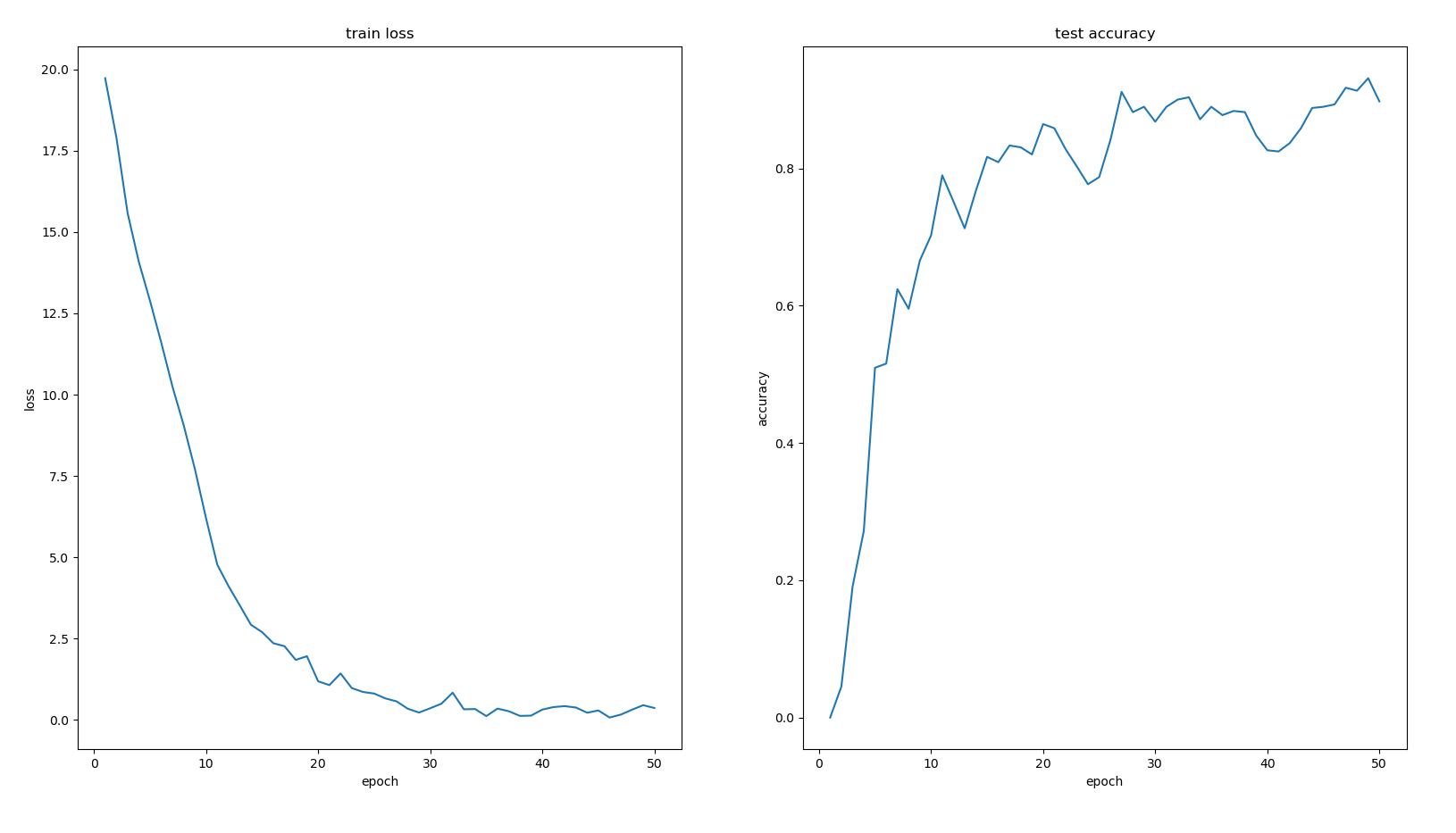
上述训练都是采用的SGD优化器,改为Adagrad优化器的结果如下,loss相比于SGD优化器,没有较大的波动。准确率相比于SGD也有较大的提升,最高为0.8647。
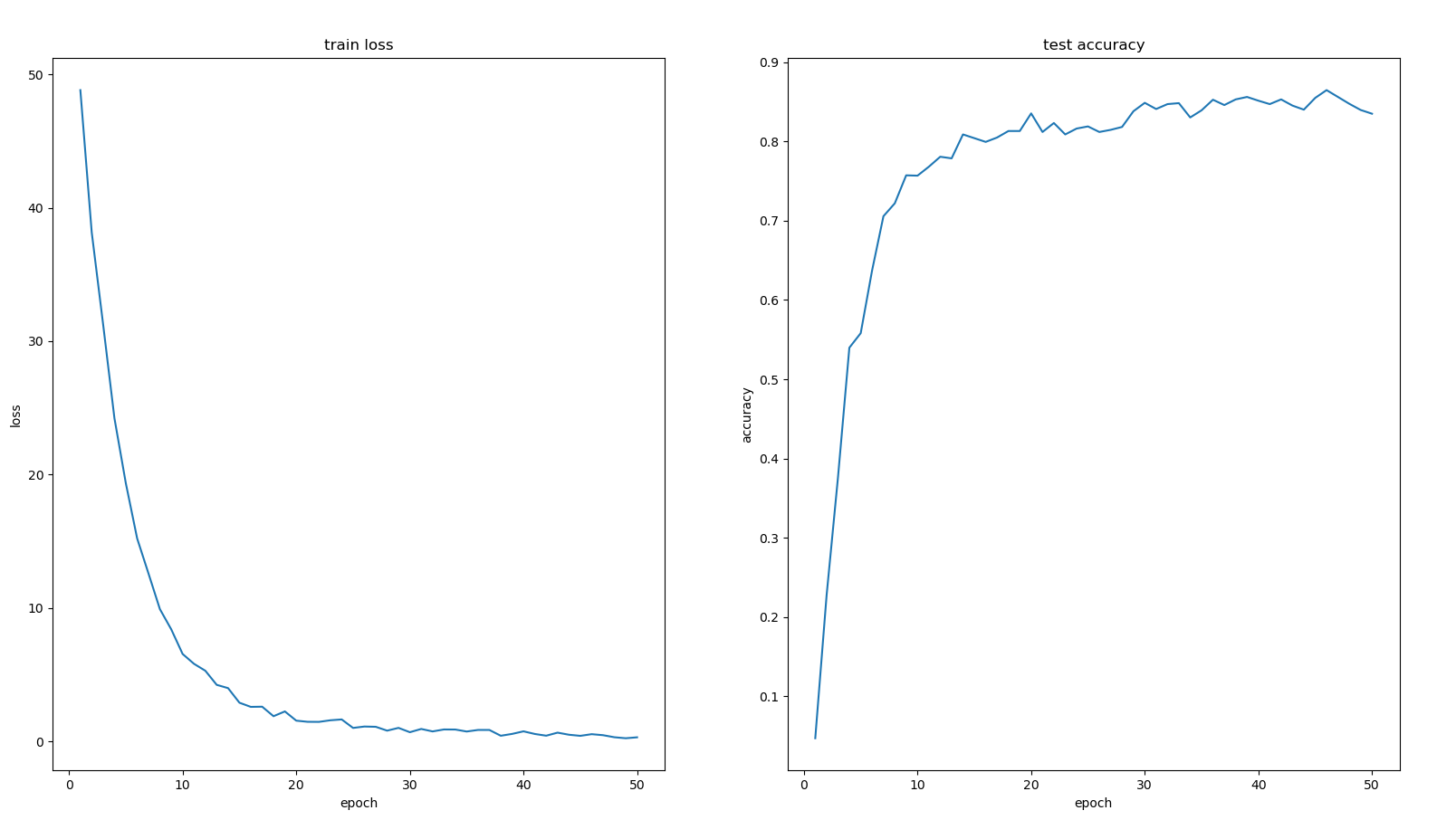
采用Adam优化器结果如下所示,其收敛速度慢于Adagrad优化器,训练500个epoch结果如下。测试集上的分类准确率为0.8777