MMCV官方文档
https://mmcv.readthedocs.io/en/latest/api.html#module-mmcv.cnn
mmdetection中使用了注册机制,使用字典进行字符串向类的映射,在norm.py中,使用了如下的代码,以norm layer为例。
1 | /mmcv/cnn/bricks/registry.py |
build_norm_layer函数,通过type”BN”返回提前注册的类nn.BatchNorm2d,并用该类根据输入的num_features构造相应的归一化层,默认需要梯度(requires_grad=True)。
Pytorch源码学习
nn.Module
torch.utils.checkpoint 不缓存中间变量,时间换显存空间
ResNet源码阅读
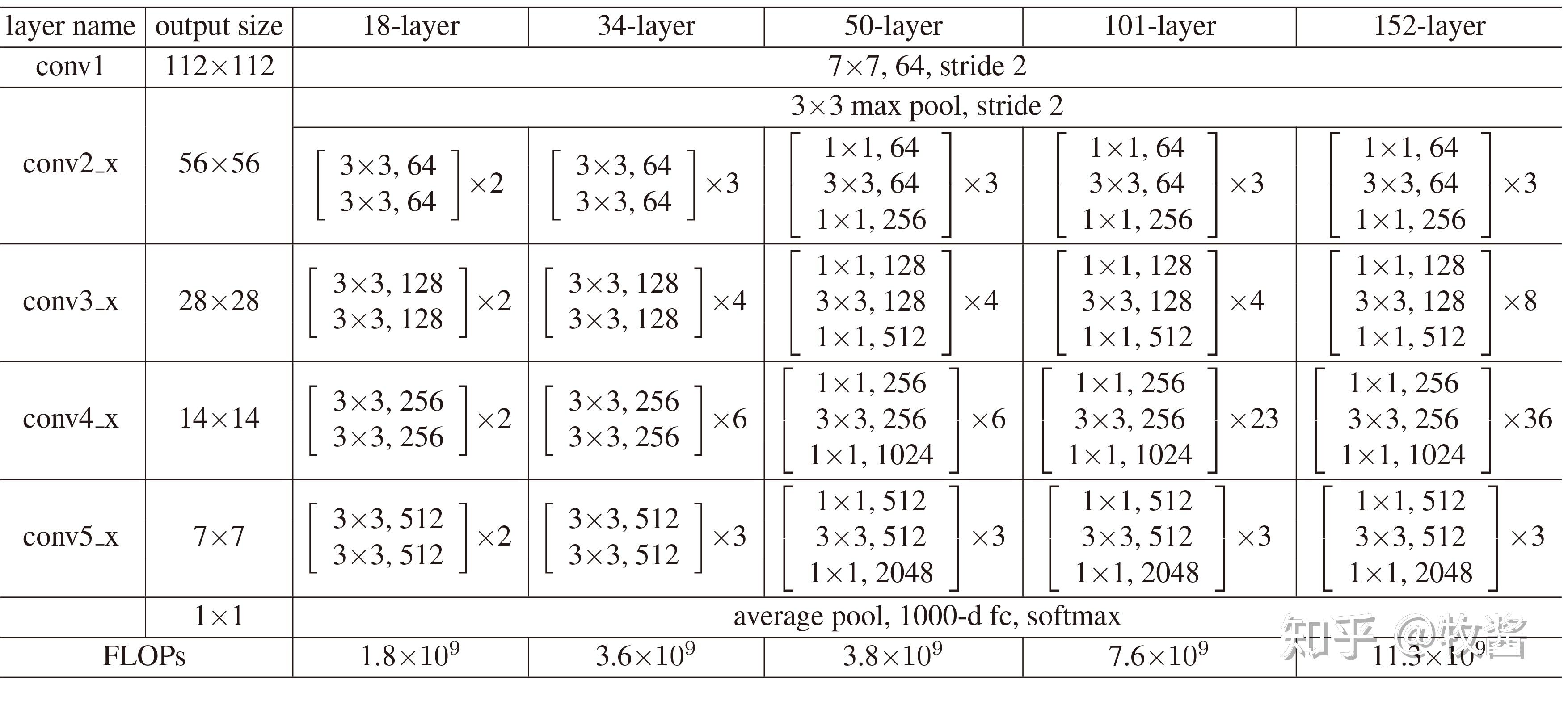
在mmcv的resnet.py文件中,对于resnet18与34,对应的block为BasicBlock,而50层以上的block为Bottleneck
卷积层分为stem与四个stage,stride=(1, 2, 2, 2),stride=2是第一个3x3的卷积层。在reset中,只有第一个块的stride是2,其余均为1。
self.downsample在第一层需要对原输入x进行大小与通道数的调整,后续的block不需要进行该操作。
1 | if self.downsample is not None: |
代码中的dcn为可变形卷积(deformable convlution)
_freeze_stage,将前几个stage的梯度更新设置为false,model设置为eval()模式。
block 每一个模块有num_blocks,对于blocks之间的连接,只有第一个block是进行残差学习。
在每一个block连接中,inplanes = planes * expansion,在每一个res_layer之间的连接中,planes = base_channels * 2 ** i ,在res_layer结束后,将inplanes设置为当前的planes * expansion
model.eval()
eval将dropout层设置为无效,batchnorm层的running_mean、running_var不更新。BatchNorm层的均值与方差采用momentum进行更新$\hat{x}_{new} = (1 - momentum) \times \hat{x} + momentum \times x_t$。
drop_out实现原理
1 | def dropout(X,drop_prob): |