欧拉函数
欧拉函数是小于或等于n的正整数中与n互质的数目,$\phi(1) = 1$。
通式:
$$
\phi(x)= x \mathop{\Pi}\limits_{i = 1}^{n}(1 - \frac{1}{p_i})
$$
若n是质数的p的k次幂,$\phi(n) = p^k - p^{k - 1}$,因为除了p的倍数$p * (1,2\dots p^{k - 1})$以外,其他数均与n互质。
线性筛,每个合数通过其最小的质因数筛掉。
二维凸包, 凸多边形是指所有内角大小都在$[0, \pi]$范围内的简单多边形。在平面上能包含所有给定点的最小凸多边形叫做凸包。
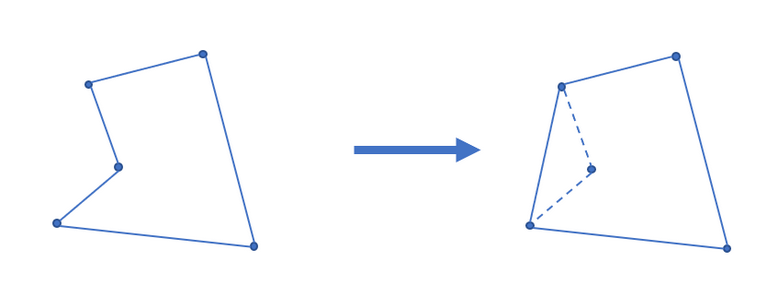
$\quad\quad$首先将点集按照x坐标(第一关键字),y坐标进行升序排列。显然排序后最小的元素和最大的元素一定在凸包上。他们之间的部分可以分成上下两条链分别求解。求下链时只要从小到大遍历排序后的点列,求上链从大到小遍历即可。
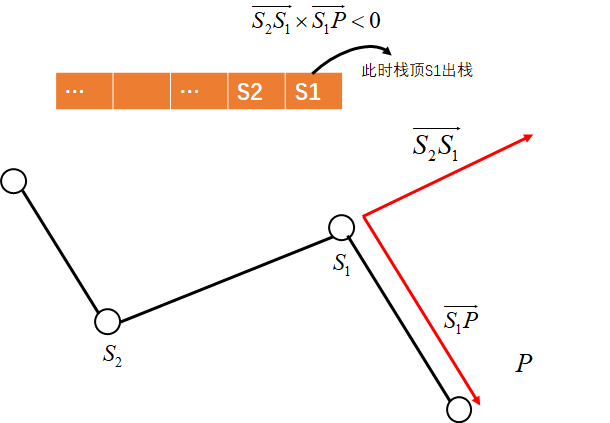
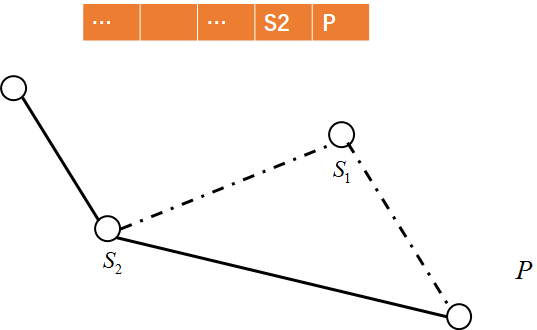
$\quad\quad$在凸包上,我们从一个点出发逆时针走,轨迹总是左拐的,如果出现右拐,则说明该段不在凸包上。采用栈来记录轨迹上已经走过的点,如果即将入栈的点$P$和栈顶点$S_1$构成的向量方向相较$S_2, S_1$构成向量的方向向右旋转,即叉积$\vec{S_2S_1} \times\vec{S_1P} < 0$,则弹出栈顶,直到$\vec{S_2S_1} \times\vec{S_1P} \geq 0$或栈内仅包含一个元素。
1 | struct Point { |
跳跃表是一种有序的数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。跳表的期望空间复杂度为$O(n)$,跳表的查询,插入和删除操作的期望时间复杂度都为$O(logn)$。
链表加多级索引的结构就是跳表。跳表的每一层都是一个有序链表,每层位于第i层的节点有p的概率出现在第i+1层,p为常数。
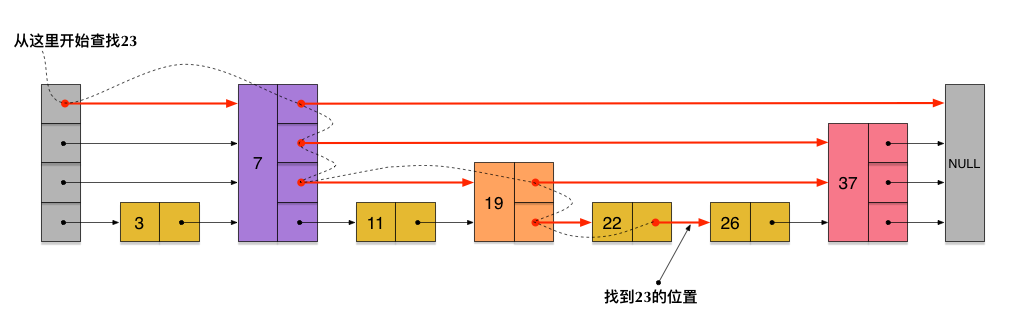
第一层的期望值为$n$, 第二层的期望值为$np$, 第三层的期望值为$np^2$,因此空间复杂度的期望值为$\sum\limits_{i = 0}^{+\infty}np^i=\frac{n}{1 - p}$。因为p为常数,因此跳表期望的空间复杂度为$O(n)$。
时间复杂度
跳表最后一层节点的个数为$\frac{1}{p}$,因为再上一层的期望值为1(无意义)。因此层数m为
$$
np^{m - 1}=\frac{1}{p} \\
(\frac{1}{p})^m=n \\
m = \log_{\frac{1}{p}}n
$$
跳表skiplist的平均查找长度,查找长度指的是查找路径上跨越的跳数,查找过程中的比较次数等于查找长度加1(每比较一次要么向下一层,要么到本层的右侧节点)。每个节点在进行插入的时候,它的层数是由随机函数randomLevel()计算出来的,随机的计算不依赖于其它的节点,每个节点是独立同分布的,每次插入过程都是完全独立的。
为了计算查找长度,我们将逆向还原查找过程,从右下方第一层最后到达的那个节点开始,沿着查找路径向左,向上回溯。假设当回溯到某个节点的时候,它才被插入,这虽然相当于改变了节点的插入顺序,但从统计上不影响整个skiplist的形成结构。
如果某一个节点有上层节点的话,则我们需要向上走,整个查找过程类似楼梯的形状,每个节点第一被访问一定是位于其最顶层。
用C(k)表示向上攀爬k个层级所需要走过的平均查找路径长度,因此有
$$
C(k) = (1 - p)*(C(k) + 1) + p * (C(k - 1) + 1) \\
C(k) = \frac{1}{p} + C(k - 1) \\
C(k) = \frac{k}{p}
$$
n个节点跳表的层数为$\log_{\frac{1}{p}}n$, 因此所需时间为$\frac{\log_{\frac{1}{p}}n}{p}$,即平均时间复杂度为$O(\log n)$
数据结构SkipListNode,skiplist真正有数据只有下面一层的数据节点,每个节点的后继就是level[0],
1 | struct SkipListNode { |
1 | class Skiplist { |
http://zhangtielei.com/posts/blog-redis-skiplist.html
反射是为了解决运行期,对某个对象一无所知的情况下,调用其方法,JVM为每一个加载的class创建一个Class类型的实例,并关联起来。
通过Class实例获取class信息的方法称为反射(Reflection)
Java的反射API提供的Field类封装了字段的所有信息:
通过Class实例的方法可以获取Field实例:getField(),getFields(),getDeclaredField(),getDeclaredFields();
通过Field实例可以获取字段信息:getName(),getType(),getModifiers();
通过Field实例可以读取或设置某个对象的字段,如果存在访问限制,要首先调用setAccessible(true)来访问非public字段。
通过反射读写字段是一种非常规方法,它会破坏对象的封装。****
设计模式本质上是面向对象设计原则的实际运用。
费马小定理,如果p为质数,且$gcd(a,p)=1$,那么$a^{p - 1} \equiv 1 (mod\ p)$, 如果p为质数,且a,p互质,那么a的p-1次方除以p的余数等于1。
二次探测定理, 如果p是素数,且x是小于p的正整数,且$x^2 \equiv 1 (mod\ p)$,那么$x = 1$或者$x =p - 1$。
Miller-Rabin素数探测,将p-1(偶数)表示为$d \times 2^r$,其中d为奇数,如果p为素数,那么存在某个$0 \le i < r$使得$a^{d*2^{r - i}} mod\ n = n - 1$,或者$a^d = 1$。
1 | using ll = long long; |
线段树本质上开了O(4n)的空间来维护了数组区间的性质。根节点从下标1开始
1 | void build(int p, int l, int r) { |
惰性更新,当更新区间包含了当前的区间[l, r],只需要更新当前的节点并进行标记。
1 | void update(int p, int l, int r, int ul, int ur, int val) { |
可持久化并查集 = 可持久化 + 并查集 = 主席树 + 并查集
leetcode 1724 检查边长度限制的路径是否存在 II
主席树方便用来维护历史的版本信息,可以支持回退, 访问之前版本的数据结构。
并查集,常用的两种优化方法是路径压缩,按秩合并。在可持久化并查集中只会用到按秩合并,即深度小的点向深度大的点合并,保证单次查询的时间复杂度为$ologn$
1 | int tot; |
建立基础主席树
1 | void build(int &t, int l, int r) { |
查找某一个元素在主席树中的下标
1 | int query(int t, int l, int r, int x) { |
查找版本号为t元素x的祖先
1 | int find(int t, int l, int r, int x) { |
按秩合并
1 | int unite(int pre, int l, int r, int x, int father) { |
更新合并后父节点的深度
1 | void update(int t, int l, int r, int x) { |
全部代码如下, java用时329ms通过了全部测试用例, 但是用c++超时了…..不开o2优化太坑人了。
1 |
|
问题描述:
给定N个数(int范围内),一共M次询问,每次都要询问区间[[l,r]的第k大的数。 其中N, M, l, r均不超过$2\times10^5$,保证询问有答案
主席树本名可持久化线段树,也就是说,主席树是基于线段树发展而来的一种数据结构。其前缀”可持久化”意在给线段树增加一些历史点来维护历史数据,使得我们能在较短时间内查询历史数据,图示如下。
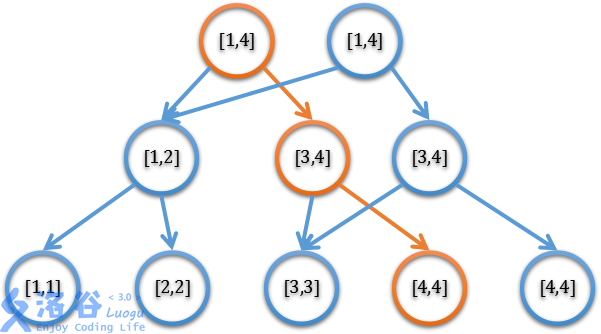
当每插入一个数据时,会修改$logn$个节点,因为主席树的左右子树节点编号不能够计算得到,而是需要记录下来。
1 | static constexpr int N = 200010 |
将数组复制一份,进行排序,去掉重复的数字离散化。
以离散化后的数组为基础建立一个全零的线段树,称为基础主席树
对原数据中每一个[1,i]区间统计,有序地插入新节点,i每增加1,就会多一个数,仅需对主席树对应的节点增加1即可
对于查询[l, r]中第k小值的操作,找到[l, r]对应的根节点,按照线段树操作的方法即可
建立基础主席树
1 | void build(int &u, int l, int r) { |
向主席树中加入元素
1 | int modify(int pre, int l, int r, int x) { |
查询区间第k大,注意区间下标是从1开始
1 | int query(int u, int v, int l, int r, int k) { |