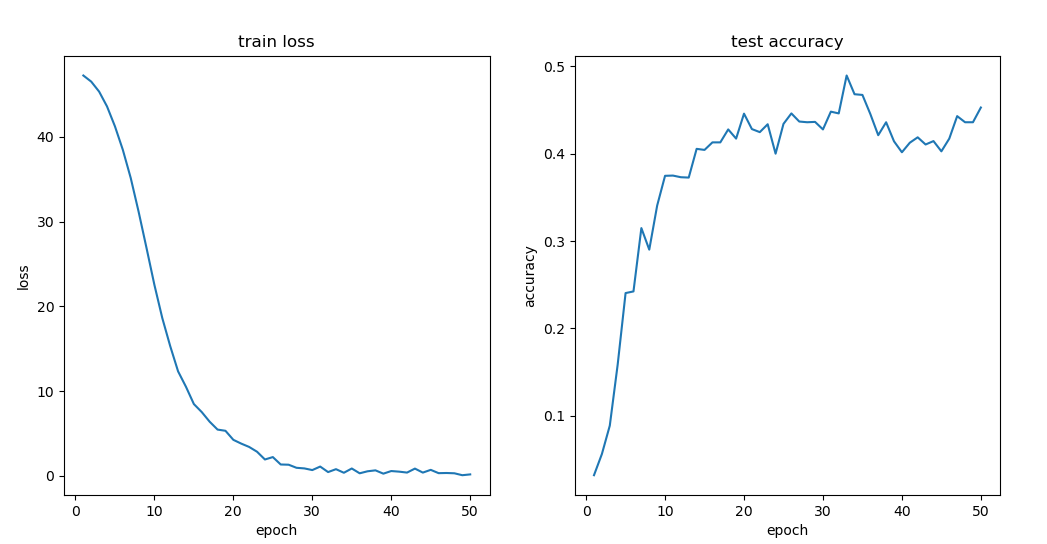
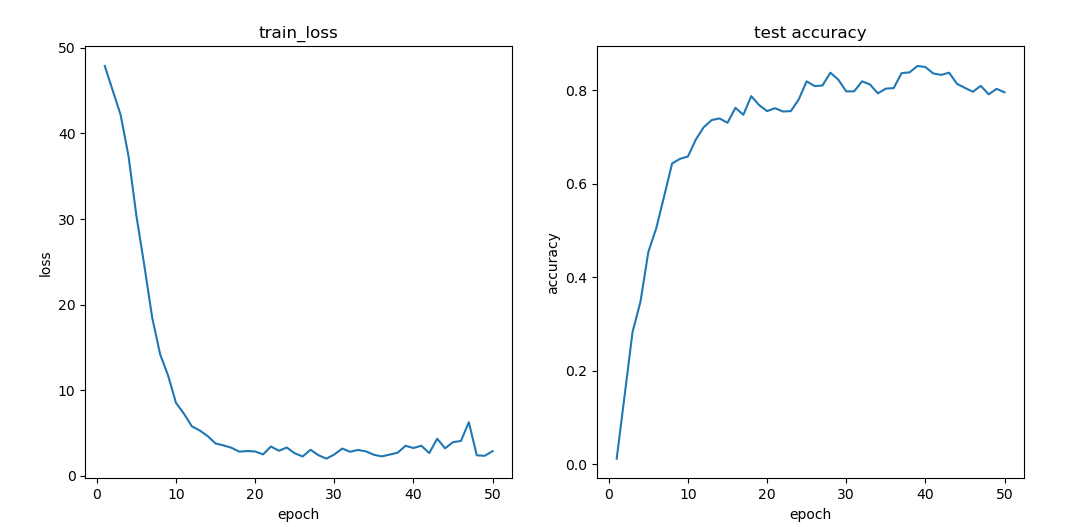
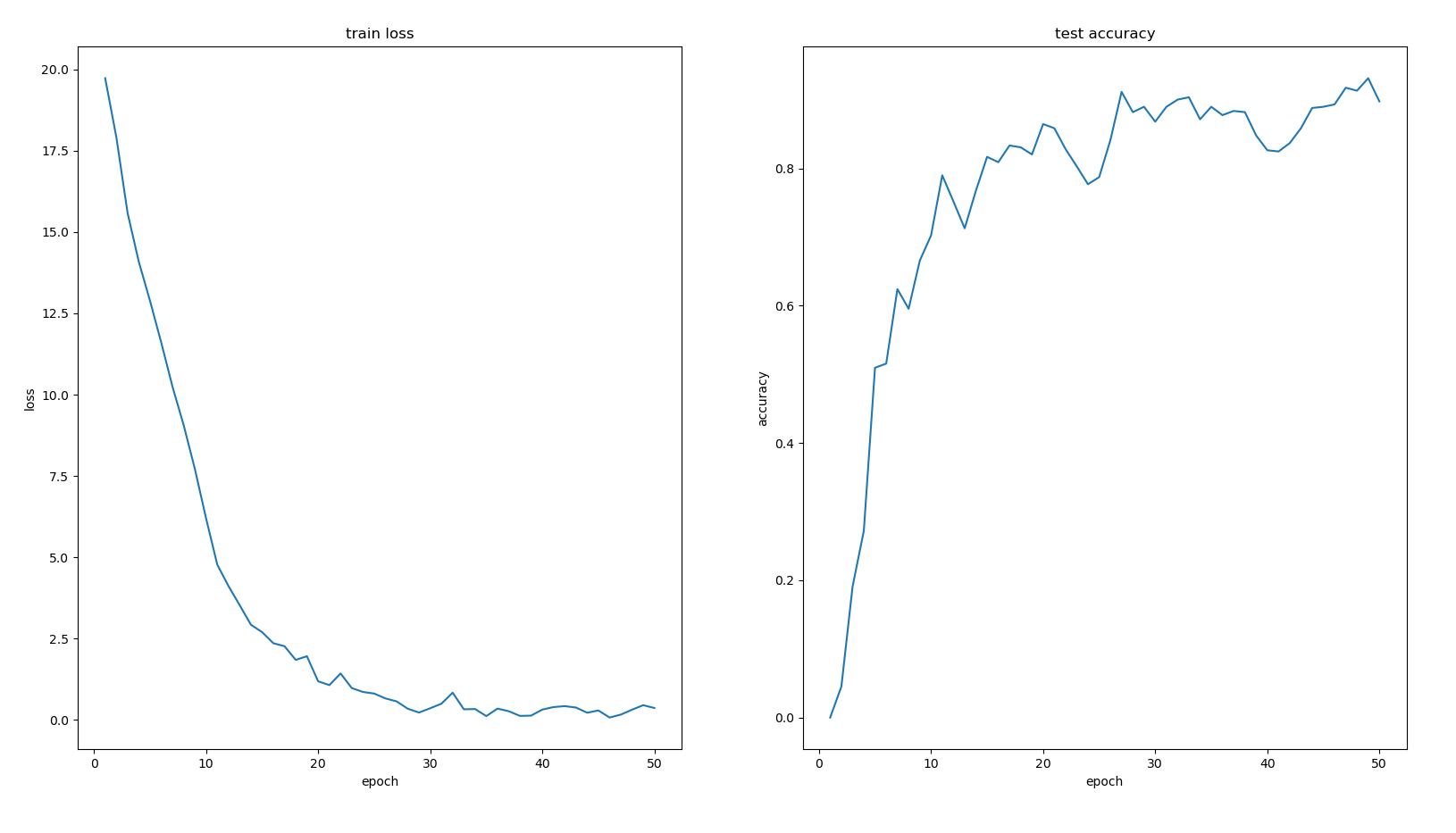
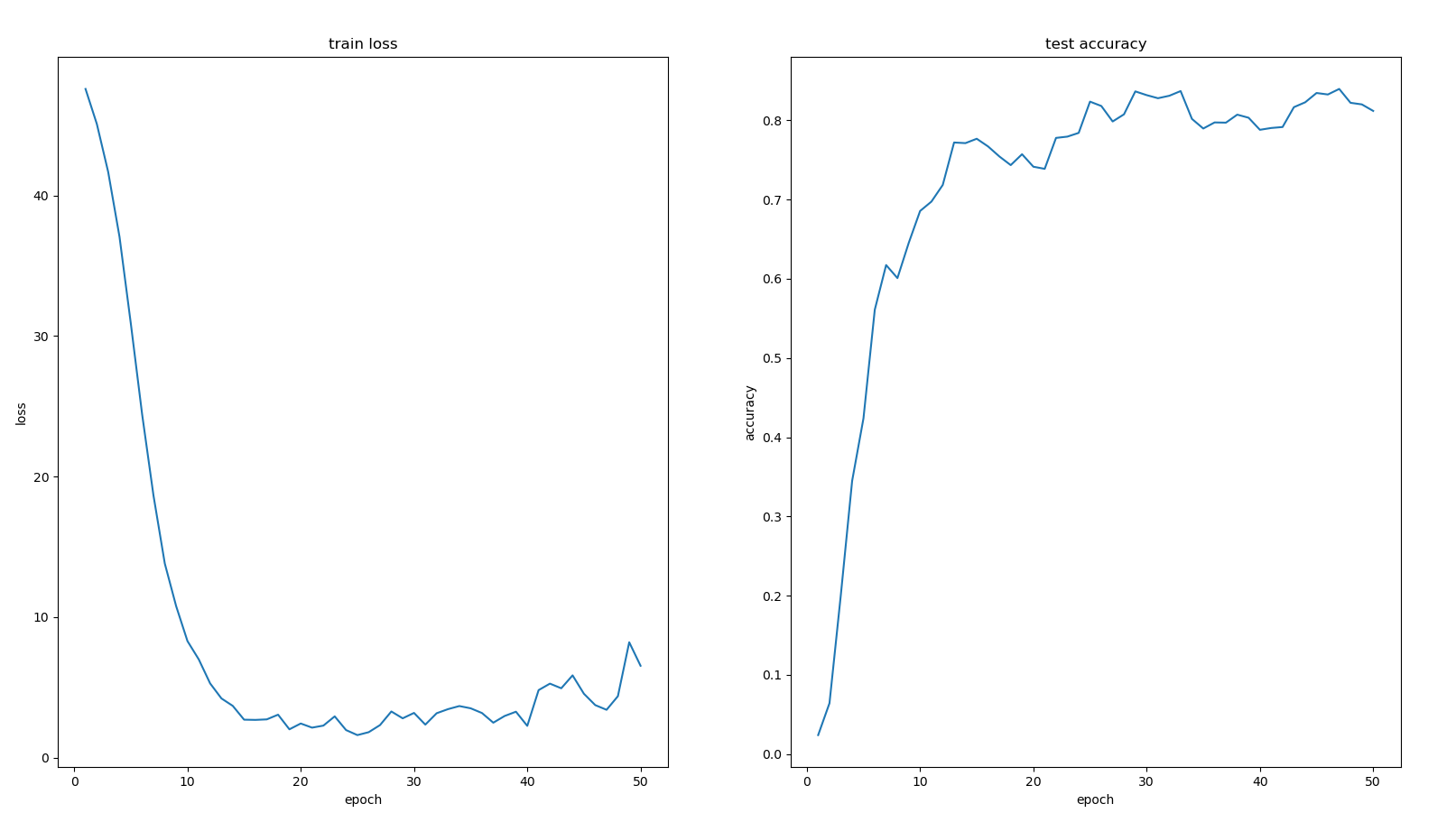
动态规划优化-单调队列
当状态转移的复杂度为$O(n)$时, 状态个数为n个,动态规划的算法复杂度为$O(n^2)$,可能会超时,因此对状态转移的过程进行优化,将状态转移的复杂度降低到$O(logn)$或$O(1)$
例1 多重背包的单调队列优化
有 N 种物品和一个容量是 V的背包。第 i种物品最多有 $s_i$ 件,每件体积是 $v_i$,价值是$w_i$。求解将哪些物品装入背包,可使物品体积总和不超过背包容量,且价值总和最大。输出最大价值。0<N≤1000
0<V≤20000
0<$s_i$,$v_i$,$w_i$≤20000
状态转移方程,可以按照体积进行分组,本质上是求一个滑动窗口的最大值。
$$
dp[j+mv] = max(dp[j] + mw, dp[j+v] + (m - 1)w, \dots, dp[j+mv])
$$
对上面的状态转移方程进行变形,采用单调队列进行优化,代码如下:
$$
dp[j+mv] = max(dp[j], dp[j+v] - w, \dots, dp[j+mv]) + mw
$$
1 |
|
例2 跳跃游戏VI
给你一个下标从 0 开始的整数数组
nums和一个整数k。一开始你在下标0处。每一步,你最多可以往前跳k步,但你不能跳出数组的边界, 达数组最后一个位置(下标为n - 1),你的 得分 为经过的所有数字之和。请你返回你能得到的 最大得分 。1 <= nums.length, k <= $10^5$
$-10^4$ <= nums[i] <= $10^4$
状态转移方程
$$
f[i]=\max_{max(0,i−k)≤j<i}{f[j]}+nums[i]
$$
该状态转移方程为$O(n^2)$,但是我们仅需要前面这个滑动窗中的最大值,因此采用单调队列的方式进行优化,使得队列头部为该滑动窗的最大值。
1 | class Solution { |